Лев Манович, Джереми Дуглас, Тара Цепель. Как сравнить между собой миллион изображений?
Лев Манович, профессор Кафедры визуальных искусств; Калифорнийский университет, Сан-Диего (UCSD). Директор Инициативы по изучению компьютерных программ (softwarestudies.com). Калифорнийский институт телекоммуникации и информации (Calit2).
Джереми Дуглас, доктор (Инициатива по изучению компьютерных программ).
Тара Цепель, кандидат наук (история теория и критика в искусствоведении, UCSD).
Перевод статьи опубликован в 9-м номере журнала «Здесь».

Вступление
Описание совместного исследования NEH / NSF «Проблема глубокого исследования данных» (2009), организованного Управлением Digital Humanities в Национальном фонде гуманитарных наук (федеральное агентство США, финансирующее гуманитарные исследования), открывалось следующими вопросами: «Как методы масштабирования влияют на исследования в области гуманитарных и социальных наук? Теперь, когда ученые имеют доступ к огромным хранилищам оцифрованных данных (в гораздо большем количестве, чем они смогли бы охватить вниманием за всю жизнь), что это значит для исследований?» Год спустя в статье из The New York Times (от 16 ноября 2010 г.) был заголовок: «Что станет следующей большей идеей в языке, истории и искусстве? Данные».
То, что мы располагаем оцифрованным архивом исторических документов, безусловно, является большим достижением, если сравнивать с традиционно малыми объемами данных, которые задействуют исследователи гуманитарных областей. Однако ученые и критики, занимающиеся современной культурой, получили ещё большую проблему. Исключая Google Books, размер цифровых исторических архивов обычно гораздо меньше по сравнению с тем количеством цифровых объектов, которое производят современные работники культуры и пользователи социальных сетей (компьютерная графика, веб-сайты, блоги, ролики на YouTube, фотографии на Flickr, публикации в Facebook, сообщения в Twitter и другие виды профессиональных и социальных медиа). Эта количественная перемена столь же важна, как и другие фундаментальные последствия политических, технологических и социальных процессов, которые начались после окончания «холодной войны» (например, бесплатная телефонная связь между любыми точками мира). В более ранней статье я описал это следующим образом:
Экспоненциальный рост числа как непрофессиональных, так и профессиональных медиа за последние десятилетие создал принципиально новую культурную ситуацию, а также явился вызовом нашим обычным способам отслеживания и изучения культуры. Сотни миллионов людей регулярно создают культурный контент и обмениваются им — блогами, фотографиями, видео, онлайн-комментариями и дискуссиями, и т. д. В то же время быстрый рост профессиональных образовательных и культурных учреждений во многих недавно глобализованных странах вместе с доступностью связанных с культурой новостей в Интернете и повсеместным распространением средств массовой информации и программного обеспечения привёл к сильному увеличению числа специалистов по культуре, участвующих в глобальном культурном производстве и обмене мнениями. Раньше теоретики культуры и историки могли строить теории и исторические описания на основе небольших корпусов данных (например, «Итальянский ренессанс», «классическое голливудское кино», «постмодернизм» и т. д.), но как мы можем отслеживать «глобальные цифровые культуры» с их миллиардами культурных объектов и сотнями миллионов участников? Прежде можно было писать о культуре, следуя тому, что происходило в небольшом количестве мировых столиц и школ. Но как мы можем следить за развитием событий в десятках тысяч городов и учебных заведений? [Манович, Культурная аналитика, 2009].
Наличие больших оцифрованных собраний гуманитарных данных безусловно позволяет исследователям использовать вычислительные инструменты, поскольку рост социальных сетей и глобализация профессиональной культуры просто не оставляют нам другого выбора. Но как мы можем исследовать закономерности и отношения между наборами фотографий, проектов или видео, объемы которых могут исчисляться сотнями тысяч, миллионами или миллиардами единиц? К лету 2010 года Facebook содержал 48 миллиардов фотографий; deviantart.com, ведущий сайт для непрофессионального искусства, разместил 100 миллионов объектов; coroflot.com, сайт для профессиональных дизайнеров, имел 200000 портфолио.
В 2007 году мы создали новую лабораторию под названием «Лаборатория по исследованию софт-культуры » (http://www.softwarestudies.com) — в Калифорнийском университете, Сан-Диего (UCSD) и Институте телекоммуникаций и информации, Калифорния (Calit2) для решения этих проблем. (В 2016 году мы изменили её название на «Лаборатория культурной аналитики» — ЛМ). Мы разработали ряд методов и техник для анализа и визуализации больших наборов изображений, видео и интерактивных визуальных произведений. В этой статье описывается наш ключевой метод, который состоит из двух частей: 1) автоматический цифровой анализ изображений, который генерирует числовые описания различных визуальных характеристик изображений; 2) визуализации, которые показывают полный набор изображений, созданный этими измерениями.
Мы уже успешно применили вышеописанный метод для исследования многих типов визуальных сред: комиксов, веб-комиксов, видеоигр, виртуальных сред, видеороликов, фильмов, мультфильмов, компьютерной графики, печатных журналов, картин и фотографий. Примеры включают 167 000 изображений из группы Art Now Flickr, 100 часов геймплея Kingdom Hearts и 20 000 страниц Science и Popular Science (1872-1922). (Более подробную информацию и другие проекты см. в разделе Digital Humanities нашего лабораторного блога http://www.softwarestudies.com; вы также можете найти визуальные модели на сайтах YouTube и Flickr по адресу: http://www.flickr.com/photos/culturevis/collections/).
Чтобы проверить, как этот метод будет работать с более крупными наборами данных, осенью 2009 года мы скачали полные собрания 883 различных серий манги с самого популярного веб-сайта для «сканов» — OneManga.com. (понятие «сканы» относится к публикациям манги, которые оцифровываются и переводятся фанатами). Мы получили все страницы, доступные для этих серий, вместе с тегами (которые указаны пользователями), отражающими жанры и целевые аудитории [см. Дуглас,Хубер, Манович, Understanding Scanlation].
Полученный набор данных содержит 1 074 790 страниц манги. Каждая страница имеет форму изображения в формате JPEG; среднее разрешение изображения — 850×1150 пикселей. Мы использовали разработанную нами программу для обработки цифровых изображений — с целью измерения ряда визуальных характеристик каждой страницы (баланс светлого и тёмного, наличие мелких деталей, характеристики текстур и т.д.) при помощи суперкомпьютеров в National Energy Research Scientific Computing Center (NERSC). «Характеристика» является общим термином в цифровой обработке изображений. Это числовое описание некоторого свойства изображения, такого как среднее значение оттенков серого или количество линий. Примечание для читателей, знакомых с анализом вычислительного текста: характеристики изображения структурно подобны текстовым характеристикам; они предлагают компактное описание данных.
В этой статье мы преодолеваем сложности работы с корпусом из миллиона страниц манги, чтобы мотивировать необходимость в вычислительном подходе для исследования собраний такого объёма и для объяснения нашего специального метода, который сочетает в себе анализ цифровых изображений и новую технологию визуализации.
Любое размышление о культуре начинается с неформального сопоставления нескольких объектов с целью понять их сходства и различия. Например, если мы хотим, чтобы наш анализ отражал весь диапазон графических методов, используемых сегодня мастерами манги в тысячах книг, миллионах страниц в этих книгах и десятках миллионов отдельных кадров, мы должны быть способны изучать детали отдельных изображений и находить закономерности различий и сходств по большим наборам изображений. Для этого нам нужен механизм, который позволил бы нам детально сравнить серии изображений любой длины — от нескольких десятков до нескольких миллионов единиц. Мы рассмотрим, как наш метод, который сочетает автоматический анализ цифровых изображений и визуализацию мультимедиа, соответствует этим требованиям.
Как сравнить между собой один миллион изображений?
Публикуемые сегодня гуманитарные исследования обычно основаны на детальном изучении небольшого числа частных случаев (которые в зависимости от ситуации могут быть литературными произведениями, телевизионными программами, фильмами, видеоиграми и т. д). Конечно, это не означает, что каждый случай рассматривается изолированно. Обычно подробный анализ таких случаев выполняется в контексте — с учётом более широкого культурного поля и с помощью знаний, приобретаемых как напрямую (например, через просмотр фильмов), так и косвенно (через чтение работ о киноискусстве). Но насколько это достоверный или полный жизненный опыт? В частности, если говорить о кино, то IMDb (www.imdb.com) содержит информацию о более чем полумиллионе фильмов, выпущенных со времен зарождения киноискусства; сколько из них было замечено учеными кинематографистами и кинокритиками? Это если не учитывать список, включающий 1 137 074 телевизионных эпизода по состоянию на лето 2001 года (см. статистику базы данных IMDb).
Тот факт, что использование малых объемов данных по-прежнему является методом гуманитарных наук по умолчанию, всё же не означает, что мы должны продолжать использовать его автоматически. Если Google может проводить анализ миллиардов веб-страниц и триллионов ссылок несколько раз в день, мы должны быть способны на большее, чем просто рассмотрение ряда отдельных случаев и их обобщение, даже если у нас нет для этого большего технических возможностей. Основная причина наличия огромной инфраструктуры, поддерживаемой Google — необходимость фиксировать динамику Интернета в режиме реального времени. В случае культурного исследования у нас нет общих требований, поэтому мы должны иметь возможность анализировать большие культурные блоки данных в условиях ограниченных ресурсов. Действительно, сегодня учёные, изучающие социальные сети, как правило, отбирают и анализируют десятки или сотни миллионов отдельных объектов (фотографии, обновления Twitter, сообщения в блогах и т. д.), задействуя очень ограниченные ресурсы [см. Ча, Квак, Родригез, Анн, Mуун — I Tube, You Tube, Everybody Tubes; Крэндалл, Бэкстром, Хуттенлохер, Кляйнберг — Отображение фотографий в мире; Квак, Ли, Парк, Муун. What is Twitter?].
Наличие в нашем распоряжении обширных блоков компьютерных данных, которые можно обработать и исследовать с использованием интерактивных интерфейсов и визуализации, открывает новые возможности. Эти возможности потенциально способны во многом изменить наше понимание культур. Вместо того чтобы быть нечётким и размытым, наше знание контекста (культурного поля как целого) может превратиться в надёжный инструмент исследования и в то же время сообщить исследованию новую глубину (предоставляя возможность сортировки и группирования миллионов артефактов по нескольким уровням). Это обогатило бы наше понимание любого отдельного артефакта, ведь мы получим возможность увидеть его на фоне точно очерченных общих схем. Это также позволит делать более уверенные заявления о поле в целом. И, возможно, самое главное — так стирается различие между точностью «внимательного чтения» и неточностями «масштабирования» — между ясным пониманием нескольких работ и очень приблизительными представлениями о поле в целом (это понимание мы обычно формируем, мысленно переключаясь между небольшим числом изученных фактов и артефактов). Он также стирает разделение между «внимательным чтением» (подробный анализ небольших текстовых единиц) и «дистанционным чтением» Франко Моретти. Это не то же самое, что определяет Моретти как «дальнее чтение» (см. его «Гипотезы о мире литературы», 2000) — анализ крупномасштабных моделей в развитии целых жанров, литературы целых стран и т. п., с использованием романа как единицы анализа (например, с помощью подсчета числа романов в разных поджанрах, опубликованных за тот или иной исторический период). Вместо выбора одной шкалы анализа, мы могли бы при желании легко охватить их все, рассматривая корпусалюбого объёма.
Любой автоматический вычислительный анализ больших собраний данных о человеческих культурах будет иметь много собственных ограничений и, следовательно, не заменит человеческую интуицию и опыт. Тем не менее, даже с учётом этих ограничений, возможности, которые он предлагает, по-прежнему огромны. Например, доступ к миллионам страниц манги должен позволить нам, в принципе, довольно надежно отобразить полный спектр графических возможностей, используемых современными коммерческими японскими художниками в жанре манга.
Такое сопоставление также позволит нам понять, какие серии манги являются наиболее типичными и уникальными стилистически; найти все серии, где графический язык со временем значительно изменяется (на сегодняшний день все самые популярные серии выходят уже на протяжении нескольких лет); исследовать, имеют ли более короткие серии и более длинные серии разные шаблоны развития; отделить художников, которые значительно меняют свои графические языки от серии к серии, от художников, не делающих этого, и т.п. Мы также сможем учесть любую гипотезу или замечание, которые будут сделаны в неофициальном порядке, когда мы будем рассматривать небольшие наборы изображений. Например, мы сможем заметить, что манга, направленная на разные гендерные группы и возрастные группы, имеет различные графические языки. Так мы увидим весь спектр.
Но как мы сможем это сделать на практике? Как мы можем сравнить между собой миллион страниц манги?
Что глаз не может видеть?
1. Начнём с того, что возьмём две страницы из подборки серий манги и рассмотрим их напрямую — без

Согласно данным OneManga.com на июнь 2010 в списке лучших 50 сериалов, доступных пользователям сайта, One Piece занимал 2 место, Vampire Knight — 13-е. Согласно www.icv2.com, в третьем квартале 2010 года One Piece был номером 2 в Японии, Vampire Knight был номером 4. Разница в рейтинге в случае с Vampire Knight, вероятно, отражает различные соотношения мужчин/ женщин-читателей манги внутри и за пределами Японии.
Мы можем, конечно, отметить много стилистических различий, сравнив эти две страницы. Например, можно увидеть, что страница из Vampire Knight содержит драматические диагональные углы, созданные как разделением кадров, так и линиями внутри них — задействована полная палитрасерых тонов от серого до почти чёрного; наличествуют большие чёрные буквы, представляющие звуки и сообщающие изображениям дополнительную визуальную энергию. У страницы One Piece, напротив, очень мало затенения; линии идут по кривой; кадры являются аккуратными прямоугольниками. Однако, как мы узнаем, существуют ли эти стилистические различия для всех 10562 страниц One Piece и 1423 страниц Vampire Knight, которыми мы располагаем? Аналогично, если мы хотим говорить о графическом стиле художника, который, возможно, произвёл на свет десятки тысяч страниц манги в десятках произведений, достаточно ли выбрать и изучить лишь несколько десятков страниц? И что, если мы хотим сравнить все shounen и shoujo manga в нашем наборе данных? Сколько страниц мы должны взять у каждой из этих категорий, чтобы сделать убедительные выводы о возможной разнице в их графических языках?
Вот ещё один пример. Предположим, мы хотим сравнить One Piece с другой очень популярной подростковой мангой: Naruto. Вот две страницы из двух серий.

Мы можем заметить определенные различия в графическом стиле между этими страницами, но насколько типичны эти различия для всех 10562 страниц One Piece и 8037 страниц Naruto, которые у нас есть? По сравнению с первым примером сопоставления, когда стили различались резко, здесь разница более тонкая — и это делает еще более проблематичным обобщение того, что мы видим на этих двух страницах.

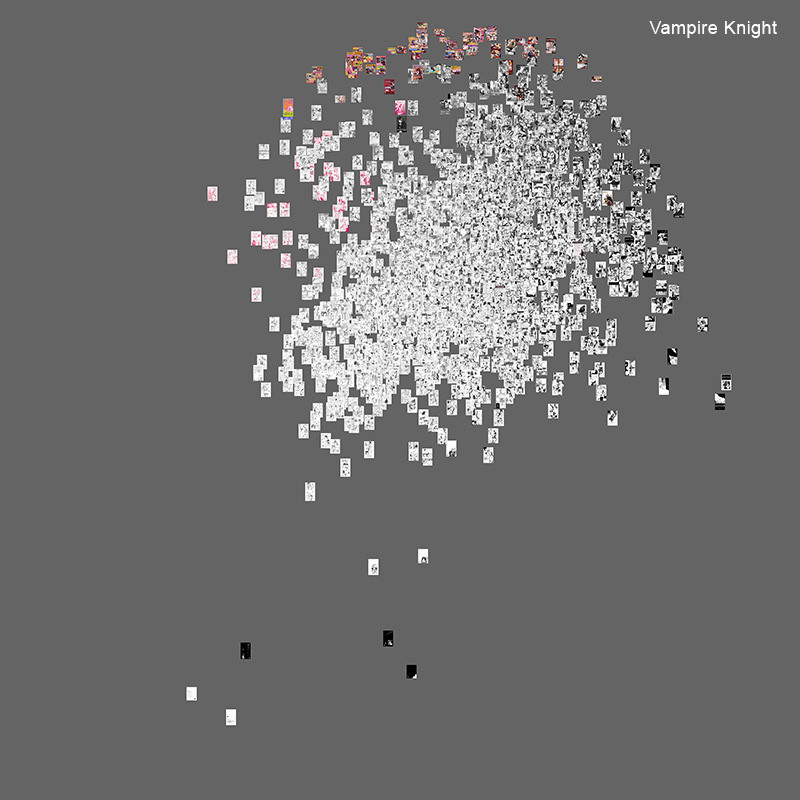
10461 страниц One Piece, которые были доступны на onemanga.com на осень 2009 года, — это организованная последовательность публикаций (слева направо, сверху вниз). Это составное изображение (мы называем такие изображения «монтажами») включает специальные страницы, вставленные в качестве «сканов» (некоторые из них выглядят как чёрные квадраты, если посмотреть небольшую версию визуализации). Примечание. Чтобы разместить все страницы в прямоугольной сетке, некоторые из страниц были обрезаны.
Если мы случайным образом рассматриваем только небольшое количество изображений из гораздо более объёмной выборки, то мы не можем быть уверены, что наши наблюдения относятся ко всему комплексу. Например, в случае нашего миллиона страниц (который сам по себе является лишь малой частью всей манги, публикуемой на коммерческой основе) ситуация обстоит так: 100 страниц — % 0.0001 из всех доступных страниц. Независимо от того, что именно мы можем наблюдать на этих 100 страницах, у нас нет никаких оснований полагать, что мы видим общий набор особенностей данной манги.
Таким образом, первая проблема с использованиемнашего собственного восприятия для сравнения изображений с целью заметить различия и сходства состоит в том, что этот подход не масштабируется. Если мы рассмотрим только небольшую выборку страниц манги, это не позволит нам сделать общие заявления о графическом стиле «манга-бестселлеров», «shounen manga» или даже об одной длинной серии, такой как Hajime no Ippo (15978 страниц в нашем собрании данных).
Изучение только небольшого образца более обширного набора изображений также не позволяет нам понять принципы изменений и эволюции. Чтобы проиллюстрировать это, мы взяли в качестве примера три страницы из бестселлера One Piece. Страницы взяты из глав 5, 200 и 400. Серия началась в 1997 году; около 600 глав были опубликованы к концу 2010 года, новые главы выходили еженедельно. Таким образом, время, прошедшее между главой 5 и главой 400, составляет примерно восемь лет; за это время художники создали более 7000 страниц (у нашего источника данных не было точной информации о датах публикации каждой главы, и поэтому мы вынуждены их оценивать лишь примерно). Вот что можно сразу отметить, сравнивая эти три страницы, в отношении графического языка: похоже, что за эти восемь лет произошли заметные изменения, но какие именно? Была ли это эволюция, череда резких сдвигов или что-то ещё? Если у нас нет средства для сопоставления гораздо большего числа страниц между собой, мы не можем ответить на этот вопрос.

Используя некоторые систематизирующие процедуры, попробуем рассмотреть большее количество страниц на основе этих примеров. Можно выбрать каждую 100-ю страницу, чтобы лучше понять, как визуальный язык меняется со временем. Этот подход также применим для сравнения различных манг. Например, можно взять каждую 200-ю страницу Naruto и One Piece соответственно (Naruto — самая популярная манга в мире). Поскольку наш набор данных содержит приблизительно 10 000 страниц для каждой из этих серий, у нас будет 50 страниц для каждого случая. Затем мы можем изучить эти 100 страниц, чтобы описать различия между стилями этих двух серий. Или, если наша серия не очень длинная, мы можем использовать другую процедуру: выбрать одну страницу из каждой главы серии, а затем применить эти наборы страниц для сравнения серий друг с другом.
Однако такой подход не сработает, если стиль меняется от главы к главе. Страницы, которые мы взяли для нашей процедуры отбора примеров, могут неправильно отражать все эти варианты. Это фундаментальная проблема варианта с выбором ряда «представительных страниц»: данный вариант работает лишь в случае небольших наборов изображений.
Например, рассмотрите все страницы из отдельно взятой главы Abara (см. иллюстрацию ниже). Какая страница в каждой главе лучше всего отражает его стиль? Независимо от того, какую страницу мы выбрали для представления всей главы, она не будет адекватно передавать стилистические вариации на всех страницах. Некоторые страницы состоят в основном из
Конечно, если мы используем компьютер для изучения нашего набора изображений, мы больше не ограничиваемся выборкой из небольшого корпуса изображений для тщательного изучения. Современные операционные системы (такие как Windows, Mac OS, iOS и Android), программное обеспечение органайзера изображений (Picasa от Google и Apple), iPhoto и
Это должно помочь нам заметить дополнительные визуальные различия и сходства по большим наборам изображений — такой подход был тщательно проанализирован с помощью небольшого примера. К сожалению, режимы отображения, предлагаемые существующим потребительским программным обеспечением и
Конечно, если наш набор изображений имеет некоторые очень очевидные шаблоны — скажем, он состоит из изображений в трех различных стилях — эти ограниченные режимы просмотра и фиксированный порядок будут по-прежнему достаточными, и мы легко заметим эти закономерности. Но такие случаи являются скорее исключениями, чем нормой (хотя, скажем, Пикассо работал в нескольких совершенно разных стилях, но он не является показательным примером).
Альтернатива рассмотрению набора изображений неформально — независимо от того, анализируем мы несколько объектов или используем программное обеспечение для просмотра многих — это систематическое описание каждого с применением ряда терминов, а затем анализ распределения этих элементов. В гуманитарных исследованиях этот процесс называется «аннотация». Исследователь определяет словарь описательных терминов, а затем «помечает» все изображения (кадры фильма, переходы между кадрами или любые другие визуальные объекты). Параллели с популярной практикой пользователей, помещающих медиа-объекты в социальные сети (вспомните о тегах в Flickr) или добавляющих ключевые слова в сообщения из блога, очевидны (впрочем, в то время как пользователи могут добавлять любые ключевые слова по своему желанию, в академических исследованиях обычно используются «закрытые словари», где набор условий определен заранее). После того, как все изображения будут аннотированы, мы можем посмотреть на изображения, имеющие конкретные теги; мы можем отображать и сравнивать частотность тегов и проводить другие статистические наблюдения. Например, если мы аннотируем страницы манги, используя набор тегов, описывающих визуальный стиль, можно сравнить, как часто каждая стилистическая функция использовалась для страниц shounen и shoujo.
Барри Солт впервые использовал этот метод для изучения визуальных сред. Он аннотировал все снимки первых 30 минут нескольких сотен художественных фильмов 20-го века, задействовав ряд характеристик: масштаб кадра, движение камеры и угол съемки. Солт использовал небольшое количество категорий для каждой характеристики. Например, возможными типами положения камеры были панорамирование, наклон, панорамирование с наклоном, дорожка и т. д. (база данных Барри Солта). Он также записал продолжительность съемки (см. Б. Солт, Статистический анализ стилей; Стиль и технология фильмов). Затем Солт использовал описательные статистические измерения и графики для анализа этих данных. В своей очень влиятельной книге «Понимание комиксов» (1993) Скотт Маклуд использовал аналогичный метод и сравнил визуальный язык японской манги и комиксов с Запада. Он аннотировал типы переходов между кадрами в ряде серий манги и комиксов, а затем использовал гистограммы для изучения визуальных данных.
В области связи и медиа исследований есть аналогичный метод, называемый «контент-анализ». Если исследователи-гуманитарии обычно занимаются произведениями конкретного автора (ов), исследователи медиа, как правило, используют контент-анализ для изучения медиа объектов, а в последнее время — контент, создаваемый пользователями. Поэтому они более точно определяют свои образцы; они также задействуют несколько человек, чтобы «кодировать» (термин, используемый в анализе контента для обозначения аннотации) медиаматериал, а затем вычислять степень соответствия полученных разными кодерами результатов между собой. Вот пара недавних примеров применения этого метода. Херринг, Шейдт, Купер и Райт проанализировали содержание 457 случайно выбранных блогов, собранных примерно с шестимесячными интервалами в течение 2004 года «для оценки того, насколько характеристики самих блогов остаются стабильными или изменчивыми во время этого активного периода». Уильямс, Мартинс, Консальво и Айвори проанализировали персонажей из 150 видеоигр; всего 8572 символа были закодированы, чтобы «ответить на вопросы об их характеристиках пола, расы и возраста в сопоставлении с населением США». Этот метод более эффективен, чем неформальный анализ СМИ, но он страдает той же проблемой — он не позволяет охватить обширные корпуса данных. Например, Маклуд аннотировал лишь небольшое количество комиксов и серий манги. Получит ли он те же результаты с гораздо большим набором — например, в случае с нашей коллекцией из миллиона страниц манги? И даже если его результаты будут подтверждены, что делать со всеми возможными исключениями? Чтобы найти их, нам нужно аннотировать каждую отдельную страницу.
Скажем, у нас есть обученный зритель, который может исследовать страницу манги и присвоить ей соответствующие теги. Если этот зритель тратит 1 минуту на каждую страницу и работает 8 часов в день, аннотирование миллиона страниц займет почти 6 лет.
(В последнее время стало возможным задействовать краудфайндинг, чтобы ускорить этот процесс. Поскольку мы не может ожидать, что все люди будут иметь одинаковые суждения о визуальной форме или использовать теги одинаковым образом, исследователи используют статистические средства для расчета согласованности суждений всех участвующих лиц, и игнорируют результаты низкого качества. Однако этот подход имеет фундаментальное ограничение — как и любая другая попытка описать изображения с использованием естественных языков, это намного лучше работает при захвате содержимого изображений, чем в работе с формой. Мы обсудим это более подробно ниже).
Вывод: Когда мы исследуем лишь небольшое подмножество большого набора изображений, наш образец может не дать представления о всем комплекте либо неправильно отразить все изменения в комплекте; кроме того, мы не можем постепенно изучать постепенные изменения.
2. Итак, что, если мы предположим, что наш набор данных содержит не миллион изображений, а только сто? Проблема масштаба уходит. Достаточно ли теперь глазомера? Нет. Вторая проблема с использованием наших глаз заключается в том, что мы не очень хорошо регистрируем тонкие различия между изображениями. Если вы сталкиваетесь с небольшим количеством изображений, которые имеют существенные различия, ваш мозг может легко организовать эти изображения в соответствии с их визуальными различиями (здесь меня интересуют не различия в содержании, которые легко увидеть, но разница в визуальном языке). Это означает возможность разделить их на группы, ранжировать их в соответствии с одним или несколькими видами визуальных характеристик, увидеть исключения (изображения, которые выделяются среди остальных), и решить другие задачи. Например, у нас нет проблем с фиксацией различий между картинами Пита Мондриана и Тео ван Дусбурга, созданными после 1925 года. Мондриан использовал исключительно горизонтальную и вертикальную линию ориентации, в то время как ван Лисбург использовал только диагонали. Эти особенности четко разграничивают Картины Мондриана и ван Дусбурга.

Но с большим количеством изображений, которые имеют меньшие различия, мы больше не сможем выполнить эти задачи. Следующий пример иллюстрирует эту проблему. Первое составное изображение содержит все страницы из одной главы Abara Цутому Нихей. Второе составное изображение содержит все страницы из одной главы BioMega за авторством того же художника. Используют ли Abara и BioMega один и тот же стиль, или же имеются тонкие, но важные отличия (помимо размера кадров)? Например, наделена ли одна серия большим стилистическим разнообразием, чем другая? Какая страница в каждом случае является самой необычной стилистически? Даже с этим небольшим количеством страниц манги на эти вопросы уже невозможно ответить.


Вывод: даже с небольшим набором изображений мы не сможем заметить малые визуальные различия между картинками.
3. Из Abara и BioMega взято всего несколько сотен страниц. Из 883 образцов манги в нашей коллекции, 297 серии содержат более 1000 страниц, а ряд серий — более 10 000 страниц. Если нам трудно сравнить несколько десятков страниц из Abara и BioMega, то можем ли мы сделать это с сериями, которые намного длиннее? Методы аннотации / контент-анализа здесь не помогут. Чтобы использовать эти методы, нам нужно иметь достаточно тегов для всестороннего описания визуальных характеристик манги. Однако создание словаря, который мы смогли бы использовать для обозначения всех типов визуальных различий в манге — или в любой другой форме визуальной культуры — задача, проблематичная сама по себе. У нас недостаточно слов на наших естественных языках для адекватного описания визуальных характеристик даже одного-единственного изображения манги — не говоря уже о всех других типах изображений. Рассмотрим образец страницы из Vampire Knight (изображение первое слева, иллюстрация выше). Можем ли мы описать все варианты фоновых текстур на четырёх кадрах? Или различия между рендерингом волос в каждом из этих кадров?
Это третья проблема при изучении визуального искусства, визуальной культуры и визуальных медиа с использованием традиционных гуманитарных подходов. Независимо от методологий и теорий, используемых в каждом отдельном случае, все они задействуют одну репрезентативную систему (естественный язык) для описания другой (изображения). Но, как показывает последний пример, мы не сможем дать имена всем вариациям текстур, композиций, линий и фигур, используемых даже в одной главе Abara, не говоря уже о миллионе страниц манги. Мы можем приступить к традиционным подходам, пока ограничиваемся обсуждением иконографии и других отчётливых визуальных элементов, которые имеют стандартизованные формы и значения: капли воды, обозначающие стресс, пульсирующие вены, означающие гнев, и так далее. Но если мы на самом деле хотим начать обсуждение ряда графических и композиционных возможностей, используемых в манге, нам нужен новый вид инструмента. Это фундаментальное ограничение распространяется на все визуальные формы, созданные людьми, будь то картины, рисунки, фотографии, графические схемы, веб-страницы, визуальные интерфейсы, анимационные работы и т. д.
Вывод: естественные языки не позволяют нам ни правильно описать все визуальные характеристики изображений, ни перечислить все их возможные варианты.
РЕШЕНИЕ: ОБРАБОТКА ЦИФРОВОГО ИЗОБРАЖЕНИЯ + ВИЗУАЛИЗАЦИЯ
Чтобы решить эти проблемы, мы разработали методологию, которую мы в целом называем культурной аналитикой. Ключевой идеей культурной аналитики является визуализация как способ изучения больших собраний изображений и видео. Визуальные модели могут использовать существующие метаданные (например, сортировку по датам публикации или именам авторов), а также новые метаданные, добавленные исследователями посредством аннотации или кодирования. Однако, как мы уже говорили, добавление тегов или других аннотаций вручную имеет серьёзные ограничения: наше визуальное восприятие не может уловить тонких визуальных различий среди большого количества изображений, а естественные языки не имеют ресурсов для описания всех визуальных характеристик изображений или перечисления их возможных вариантов.
В целях преодоления этих ограничений, наш основной метод предполагает обработку цифровых изображений и новый тип визуализации. Этот раздел описывает данный метод, а в следующих мы применяем его ко всё большему количеству изображений, взятых из нашего миллионного набора данных, связанных с мангой (для описания других наших методов визуализации, см. Manovich, Media Visualization).
Метод состоит из двух этапов:
1. Мы используем обработку цифрового изображения для автоматической оценки ряда визуальных характеристик (то есть, особенностей) наших изображений. При этом визуальные качества отображаются числовым способом (в компьютерных науках этот способ часто называют «извлечением признаков»). Например, в случае серых тонов имеет место шкала 0-255, чёрный представлен как 0, белый как 255 и 50%, серый как 127,5. Примеры характеристик, которые можно измерить, включают контрастность, наличие текстуры и мелких деталей, количество линий и их кривизну, количество и тип рёбер, размер и положение фигур и т. д. В случае цветных изображений мы также можем измерять цвета всех пикселей (оттенок, насыщенность, яркость), определять наиболее часто используемые цвета и вычислять различные статистические данные изображений для цветных компонентов (R, G, B) по отдельности.
Как правило, такие измерения предполагают множество числовых значений для каждого визуального измерения картинки. Например, каждый пиксель будет иметь значение шкалы серого. Если мы измеряем ориентацию всех прямых в изображении, мы присваиваем отдельный номер каждой прямой. Чтобы иметь возможность сравнивать несколько изображений друг с другом по конкретным параметрам, удобно использовать средние значения измерения в случае с каждой характеристикой.
Скажем, если нас интересуют значения шкалы серого, мы суммируем значения всех пикселей и делим их на количество пикселей. В случае линейных ориентаций мы также добавляем углы всех линий и делим их на количество линий. Помимо использования этих простых средних величин (усреднение), мы можем также использовать другие типы описательной статистики для получения характеристик изображения. Они включают различные представления об основной тенденции в данных (медиана, режим и т. д.) и дисперсии данных (дисперсия, стандартное отклонение и т. д.).
Вот примеры такой статистики, рассчитанной для образцов страниц манги, которые уже были представлены в предыдущем разделе.

Страница Vampire Knight (слева) имеет самое низкое среднее значение оттенков серого
2. Мы создаем 2D-визуализацию, которая представляет изображения в соответствии с их признаками. Например, мы можем использовать горизонтальную развертку (ось X) для представления среднего значения в оттенках серого и вертикальную (по оси Y) для представления стандартного отклонения в оттенках серого. Эти функции изображения, рассчитанные с помощью программного обеспечения на шаге 1 стало координатами изображения в 2D пространстве. Таким образом, различия между изображениями по определенному визуальному измерению проецируются на их позиции в пространстве — приводятся к состоянию, которое наше визуальное восприятие может считывать хорошо.
Чтобы проиллюстрировать это, мы визуализируем три страницы манги из предыдущего примера, используя их средние значения и характеристики стандартного отклонения. Этот сценарий задействует лишь две очень простые функции. Поэтому мы не можем ожидать, что он даст полное представление о визуальной разнице между этими тремя изображениями. Тем не менее, даже с двумя характеристиками, пространственные позиции и расстояния между изображениями в 2D-пространстве хорошо отражают наше восприятие общих визуальных различий между изображениями: страницы One Piece и Naruto находятся рядом; Vampire Knight — далеко.
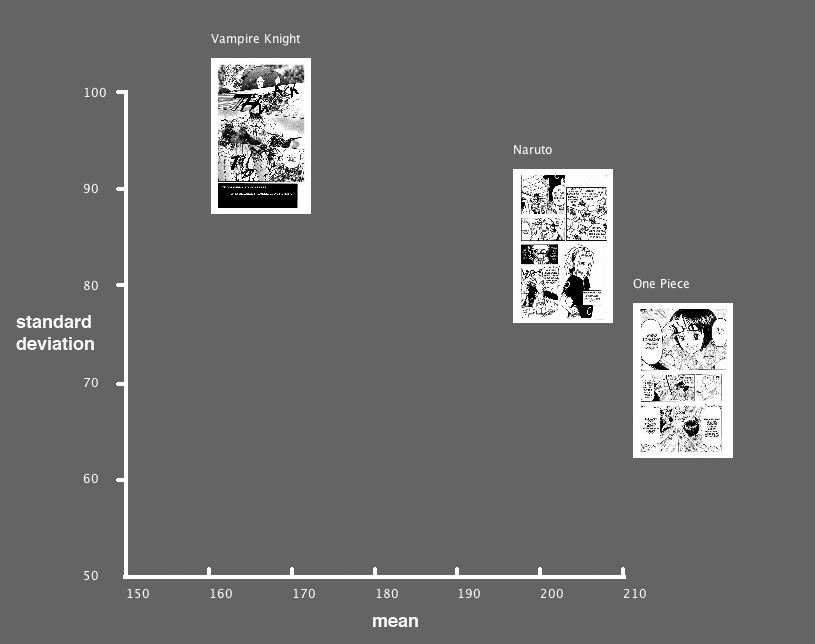
Измерение визуальных функций, а затем отображение этих признаков на оси X и Y позволяет нам обозначить общую воспринимаемую разницу в отдельных измерениях. В этом графике мы используем средние значения и разброс оттенков серого (т. е. среднее и стандартное отклонение), но мы также можем использовать многие другие параметры. Этот процесс не похож на то, как функционирует зрительное восприятие человека. Человеческая визуальная система анализирует визуальный образ отдельно с точки зрения разных характеристик: контраст, текстуры, формы, цвета и движения. Большинство психологов и нейробиологов считают, что мозг объединяет эту информацию, чтобы достичь целостности восприятия. Исследователями были предложены различные теории, которые пытались объяснить детали этого процесса. Получившая широкое распространение теория внимания, разработанная Энн Трайсман и Гарри Гелэдом, предполагает, что различные особенности, проанализированные на ранних стадиях восприятия, «привязаны» к сознательно пережитым явлениям. Другая теория (Л. Уорда) предложила нейронный механизм, ответственный за связывание признаков, которые передают форму, движение, цвета, глубину и другие перцептивные аспекты. Некоторые из функций, которые мы измеряем, такие как фильтры Габора, считаются точными эквивалентами характеристик, анализируемых головным мозгом; другие могут быть поняты как эквивалент комбинации множества признаков, вычисляемых мозгом.
Как мы говорили ранее, когда мозг сталкивается с рядом очень похожих изображений или большим их количеством, он не может точно отображать различия между ними. Когда мы измеряем функции в наборах изображений и визуализациях в соответствии со значениями функций, мы, в сущности, усиливаем человеческое восприятие; то есть расширяем способность оценивать визуальные различия. Комбинация цифрового анализа изображений и визуализации позволяет обойти проблему, которая частично присутствовала в визуальной семиотике, а также во всех лингвистических попытках описания визуального в целом: неспособность языка адекватно представлять все вариации, которые могут содержать изображения. Например, даже если мы используем сотни слов для цветов, изображения могут содержать миллионы цветовых вариаций. И цвет не является наиболее показательным примером; для других характеристик, таких как текстура или линия, представленные естественными языками термины гораздо более ограничены.
Другими словами, наши чувства способны регистрировать гораздо больший набор значений для любого параметра (громкость, шаг, оттенки серого, цвет, движение, ориентация, размер и т. д.) чем наши языки способны отобразить. Это естественно, потому что язык пришел в дополнение к чувствам значительно позже их самих. Язык делит непрерывный мир на более крупные дискретные категории, что делает возможным абстрактные рассуждения, метафоры и другие уникальные приемы. Он не предназначен для перевода всего богатства нашего сенсорного опыта в другую репрезентативную систему. Поэтому, если мы не можем полагаться на естественный язык, чтобы фиксировать то, что могут регистрировать наши чувства (а на чувства мы не можем полагаться, потому что, как мы увидели в предыдущем разделе, они не могут регистрировать тончайшие различия между изображениями или другими культурными артефактами), то как мы можем говорить о визуальной культуре и визуальных медиа?
Наш подход заключается в использовании визуализации в качестве новой описательной системы. Другими словами, мы описываем изображения с помощью изображений. При этом мы используем способность изображений регистрировать тонкие различия в любом визуальном измерении.
Обратите внимание, что наш метод не означает, что мы избавляемся от дискретных категорий. Скорее, вместо того, чтобы ограничиваться тем малым количеством категорий, которые нам предоставляют языки, мы можем теперь получить их столько, сколько нам требуется.
Скажем, мы хотим описать уровни оттенков серого в изображении. Мы используем программное обеспечение для считывания пиксельных значений из файла изображения и вычисляем среднее значение. Это среднее значение затем используется для определения позиции изображения в визуальной модели вдоль оси X или Y.
Общие 8-битные и 24-битные форматы изображений, такие как JPEG и PNG, используют 256 дискретных значений для представления оттенков серого. Это дает нам 256 отдельных категорий для значений оттенков серого. Эти категории не маркированы разными наименованиями. Но они работают — они позволяют нам сравнивать несколько изображений с точки зрения их оттенков серого.
Мы не ограничены 256 категориями — если мы хотим, мы можем использовать 1000, 10 000 или любое другое количество. Как это работает? Когда мы вычисляем среднее значение всех значений целых градаций серого, мы получаем реальное число. Например, если изображение содержит четыре пикселя со значениями шкалы серого 103, 106, 121 и 112, средний показатель этих значений составляет 102 + 107 + 127 + 113) / 4 = 109,75. Если мы обойдём эти цифры с использованием одного десятичного знака, у нас будет 256×10 = 2,560 различных категорий. Если мы сохраним два десятичных разряда, у нас будет 25 600 дистанционных категорий. В действительности, нам не нужно идти так далеко, поскольку человеческое восприятие не может видеть разницу даже между двумя уровнями серого, которые находятся рядом (например, 127 и 128) по шкале 0-256.
Хотя мы задействуем различные методы визуализации, ключевым методом, используемым нами, является точечный график, т. е. двумерное визуальное представление, которое использует декартовы координаты для отображения двух наборов числовых значений, описывающих данные. В нашем случае каждый элемент набора данных является изображением, а два значения, определяющие его положение на графике, представляют собой два измеренных визуальных качества (признака), таких как средние оттенки серого и стандартное отклонение.
В равной степени мы используем линейные графики, где ось X представляет даты, в которые были созданы изображения (или их позиции в повествовательной последовательности, такой как комикс), а ось Y представляет собой некоторые характеристики (например, средняя насыщенность).
Наряду с регулярными диаграммами рассеяния и линейными графиками мы также задействуем новый метод визуализации, который мы называем графиком изображения. Нормальный график рассеяния и линейный график отображают данные как точки и линии.
График изображения накладывает изображения на точки данных в графике.
Следующие изображения 127 картин Пита Мондриана иллюстрируют разницу между разбросом и графиком изображения.
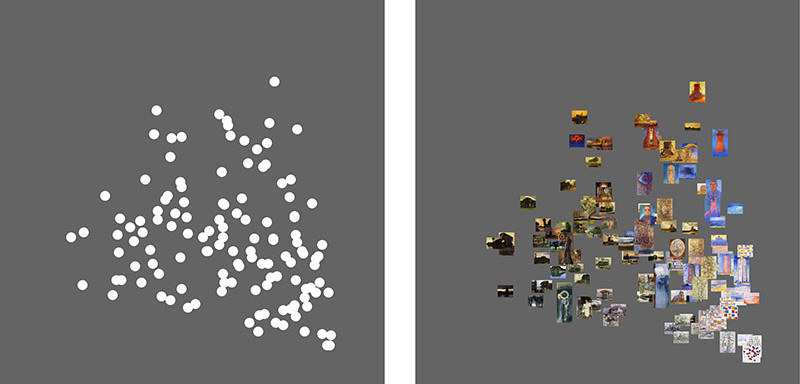
Технические детали: Мы также используем более совершенные методы визуализации, такие как матрица рассеянного графика и параллельные координаты, а также многомерные методы анализа данных, такие как PCA, кластерный анализ, и так далее. Однако, поскольку понятия многомерного пространства признаков и размерности являются более абстрактными, в этой главе все наши примеры представляют собой двумерные визуальные модели, где каждая ось соответствует одной функции, такой как среднее значение оттенков серого, или метаданные, которые были собраны наряду с данными (напр., позиция страницы в последовательности всех страниц манги).
В общем, мы предпочитаем использовать отдельные функции для оси X и Y, если их график представляет репрезентативные рисунки и если их смысл легко объяснить; в отличие от этого случая, в графике, который использует PCA или другие многомерные методы, часто трудно интерпретировать измерения. Хотя метод, который мы называем «графиками изображения », уже описан в ряде статей в Computer Science (см. Петерс, MultiMatch), он не был доступен ни в одном графике или визуализации. Наша лаборатория разработала программное обеспечение для создания графических изображений; мы используем это программное обеспечение во всех наших проектах, а также распространяем его на свободный основе (Инициатива по исследованию программ, ImagePlot). Программное обеспечение работает на обычных Windows, Mac и Lunix — настольных компьютерах и ноутбуках. Работая с нашим LAN, в Gravity Lab, расположенной в Калифорнийском институте телекоммуникаций и информации (Calit2), мы создали интерактивное приложение, способное генерировать тысячи изображений в реальном времени. Приложение работает на масштабируемых панельных дисплеях, таких как HiperSpace (высокоинтерактивное параллельное пространство отображения), который обеспечивает разрешение 35 840×8000 пикселей (287 мегапикселей) на дисплейной стене шириной 31,8 футов и высотой 7,5 футов из 70 30-дюймовых мониторов (Ямаока, Манович, Дуглас, Кюстер, Культурная аналитика в крупномасштабной визуализации медиа). В этой статье все графические изображения выполняются с помощью программного обеспечения ImagePlot; разброс участков и линейные графики осуществляются с помощью ImagePlot и Mondrian (бесплатное программное обеспечение для визуализации данных).
В следующих разделах этой статьи мы покажем, как наш метод можно использовать для сравнения между собой наборов изображений, включающих от нескольких сотен до миллиона единиц.
Сравнение Abara и Noise (474 страницы)
Введя в оборот наш метод — визуализацию изображений в виде графика рассеяния (в соответствии с количественными описаниями их визуальных свойств (характеристик), выявленных при обработке цифрового изображения), применим этот метод к нашему корпусу данных о манге.
Чтобы сделать примеры визуализации более простыми, мы будем использовать две те же самые визуальные характеристики в большинстве примеров ниже. Первая характеристика — стандартное отклонение значений оттенков серого всех пикселей в изображении. Стандартное отклонение является широко используемым показателем изменчивости. Оно показывает, несколько данные разбросаны по среднему значению. Если изображение имеет большой диапазон значений оттенков серого, оно будет иметь большое стандартное отклонение. Если же изображение использует только несколько значений оттенков серого, его стандартное отклонение будет небольшим.
Вторая характеристика — энтропия. В теории информации концепция энтропии была разработана Клодом Э. Шенноном в его знаменитой статье 1948 года «Математическая теория коммуникации». Энтропия описывает степень неопределенности данных — то есть то, насколько сложно или легко предсказать неизвестные значения данных, учитывая значения, которыми мы уже располагаем. Если изображение состоит из нескольких монохромных областей, его энтропия будет низкой. Если же изображение имеет много текстур и деталей, и его цвета (или значения оттенков серого в случае черно-белых изображений) значительно отличаются от случая к случаю, его энтропия будет высокой.
В следующих примерах мы сопоставим значения стандартного отклонения с осью X и значениями энтропии Y. Мы начнём с представления графических изображений страниц Abara и Noise. Первое произведение имеет 291 страницу; второе — 183 страницы (это число подразумевает все страницы, которые были доступны на onemanga.com, включая титульные страницы и страницы создателей).
Как видим, измерения стандартного отклонения (по оси X) и энтропии (по оси Y) действительно соответствуют перцептивно значимым визуальным характеристикам страниц манги. Страницы с низкой энтропией значения находятся в нижней области участка. Они состоят из небольшого количества плоских областей, с минимальной детализацией и отсутствием текстурирования. Страницы с высокими значениями энтропии, расположенными в верхней области участка, противоположны: у них много деталей и текстур. В горизонтальном измерении страницы, которые используют только несколько оттенков серого, находятся слева; страницы с различным показателем значений — в середине, а страницы, на которых только белый и черный, расположены справа.
Чтобы иметь возможность сравнивать диапазон значений стандартного отклонения и энтропии в обоих произведениях, мы можем построить график данных, используя стандартные диаграммы рассеяния, и поместить два случая бок о бок (Abara слева, NOISE справа).

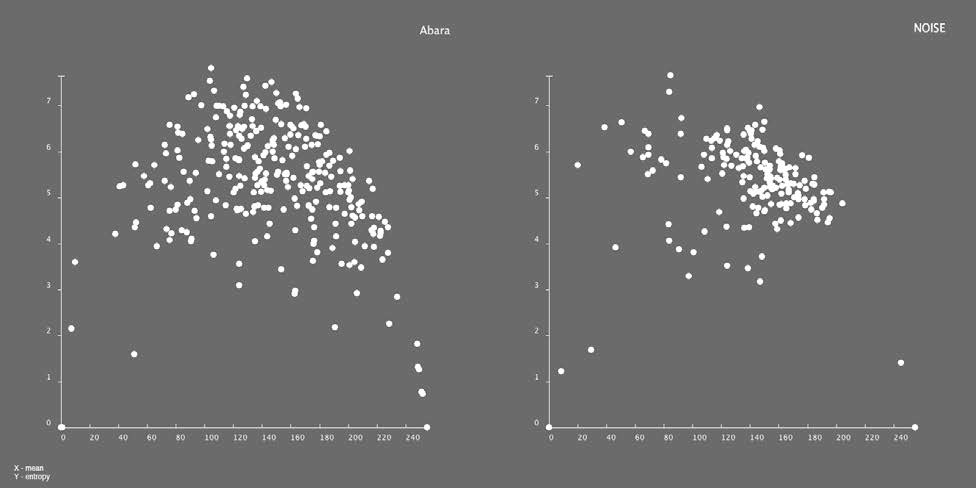
Визуальное соположение этих двух произведений упрощает ответы на вопросы, которые мы задали раньше. Является ли одно произведение более стилистически разнообразным, чем другое? Да, стиль Abara куда более разнообразен: точки на левой диаграмме более рассеяны, чем точки справа. Какая страница в каждом случае наиболее стилистически необычна? Каждый график обнаруживает определённое число исключений — точек, которые выделяются среди остальных. Конечно, нам следует помнить, что два измерительных метода, используемых нами в этих графиках (стандартное отклонение и энтропия), схватывают лишь несколько измерений визуального стиля. При использовании других параметров другие страницы могут всплыть как исключения.
Визуализация временных изменений в Abara и Noise
Манга — искусство последовательности. Чтобы понять, как изменяется визуальный стиль от страницы к странице и от главы к главе (и изменяется ли вообще), мы можем создать графики изображений, где ось Х представляет место страницы в последовательности, а ось Y использует тот или иный визуальный параметр. Если мы применим этот метод к двум названным произведениям, то сможем сравнить, как они изменяются во времени по этим параметрам.
Графики, созданные с использованием этого подхода, могут быть очень длинными. К примеру, мы хотим вывести на графике последовательность из 10000 изображений и сделать каждое из них шириной в 100 пикселей. В этом случае визуализация будет иметь размер 10,000×100 = 1000000 пикселей. Чтобы решить эту проблему, при визуализации художественных фильмов мы представляем каждый кадр отдельно. В нашей галерее на сайте Flickr вы можете найти примеры подобных графиков для полных фильмов. Для более коротких серий манги мы будем использовать как визуальные графики (со всеми страницами), так и линейные (где каждая страница представлена точкой). Первые легче читаются, последние — более эффективны в обнаружении закономерностей. Для длинных произведений мы используем линейные графики, поскольку визуальные были бы слишком длинными (линейный график необязательно использует линии, чтобы соединять элементы данных. Различия между линейным графиком и графиком рассеяния в том, что в первом данные, расположенные на оси Х, разделены одним и тем же интервалом, т.е. 1, 2, 3… А график рассеяния этого не предполагает).
Сперва мы сравним Abara (318 страниц) и Noise (140 страниц), используя простейшие визуальные характеристики: средний показатель серого от всех пикселей на странице (ось Y). Средний показатель отражает соотношения белой, серой и чёрной областей. Мы пронумеровали все страницы, начиная от заглавной и заканчивая последней в серии (мы удалили дополнительные страницы, вставленные фанатами, которые отсканировали и перевели эти выпуски; мы также удалили «бонусные» главы). Страницы располагаются слева направо с использованием этой линейной последовательности (ось Y).
В Японии выпуски манги сначала публикуются в журналах, которые могут выходить еженедельно, раз в две недели или раз в месяц и содержать новые главы для новых выпусков. Затем некоторые главы из выпусков манги, имевших успех, выходят в отдельном томе (tankōbon). Эти выпуски переводят на другие языки и публикуют в одном формате (номера глав указывают только в одном из томов). Фанаты со всего мира, читающие урезанные версии манги через Интернет, могут продолжать чтение, несмотря на то, что порядок глав известен только по одному изданию. Визуальная модель, которая расставляет главы по порядку в короткие серии, как это, например, происходит в Abara или NOISE, предполагает именно такой режим чтения.
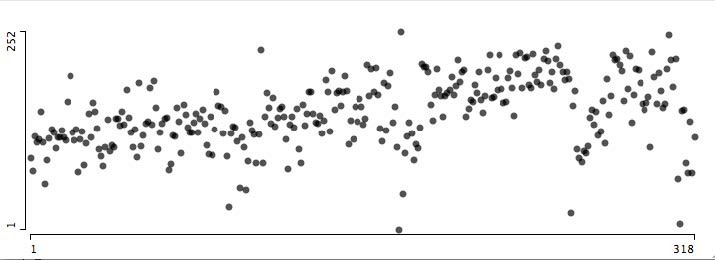

Обе визуализации используют одинаковые единицы измерения для оси Х, именно поэтому первый график (Abara, 318 страниц) вдвое длиннее второго (NOISE,140 страниц). Точки соответствуют каждой отдельной странице; они соединены линиями для того, чтобы было нагляднее.
Сравнив два выпуска, созданных одним и тем же художником, расположив их рядом, мы видим их сходства и различия в рассредоточении на графике. График Abara по большей части переходит к линейному виду ближе к последним страницам. График NOISE несущественно начинает подниматься к середине — в пятой главе, а затем снова идёт вниз. Тем не менее средние показатели серого нигде не поднимаются так высоко, как на графике Abara.
Чтобы помочь нам разобраться с графическими областями в каждой главе, графический дизайнер Он Киан Пен (Мультимодальная Аналитическая Лаборатория, Сингапурский Национальный университет) визуализировал последовательность страниц манги NOISE в виде гистограммы. Каждая глава выделена отдельным цветом, кроме того, главы разделены горизонтальными интервалами. К тому же в график не включены изображения с картинками (имеются в виду начала глав), поэтому он фокусируется на областях с обычными повествовательными страницами.
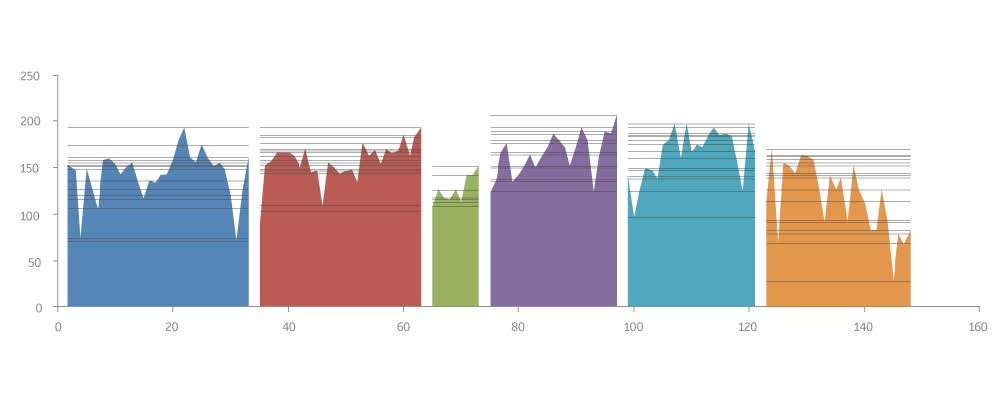
Две следующие визуализации сравнивают стилистическое развёртывание Abara и NOISE по следующим параметрам: низкая детализация/текстурированность — высокая детализация/текстурированность. Так выявляется уровень энтропии — упорядоченности элементов. Ниже мы видим график NOISE, сведённый к такому же масштабу, что и Abara. Это делает графики более показательными.

В обоих произведениях степень упорядоченности изменяется со временем. Область, фиксирующая эти изменения в NOISE, может быть описана как линейное постепенное смещение по нисходящей. Подобная область в Abara устроена сложнее. Её можно описать как горизонтальную линию, представляющую собой кривую, которая сперва идёт вверх, а потом вниз. Временные области имеют одно интересное сходство. В каждом графике расстояние между верхними и нижними точками (т.е. разница между их величинами на оси Х) постепенно увеличивается. Это означает, что стилистически страницы сначала достаточно похожи, а со временем становятся всё более различными (к тому же стоит помнить, что мы описываем только стилистическое измерение).
Чтобы подробнее показать важную временную область, которая становится видимой через особенности характеристик, мы отклонимся в сторону от нашей выборки в миллион страниц манги для следующего примера. Посмотрим на
В следующем изображении на оси Y положение каждой страницы обусловлено средним значением величины серого, исходя из всех пикселей на странице.


Несмотря на недельные интервалы, которые разделяют 6-страничные эпизоды Freakangels, визуальная модель показывает, что страницы замечательно согласованы. Для большей части публикаций изменения средних значений оттенков серого следуют плавной кривой (то же самое относится к оттенку и насыщенности, если мы их рассмотрим). Хотя переход от более светлых к более темным изображениям соответствует развитию истории от дневного эпизода к ночному, тот факт, что значения оттенков серого сдвигаются поступательно и систематически в течение многих месяцев, является подлинным открытием. Визуализация иллюстрирует это открытие и позволяет нам видеть точную форму кривой.
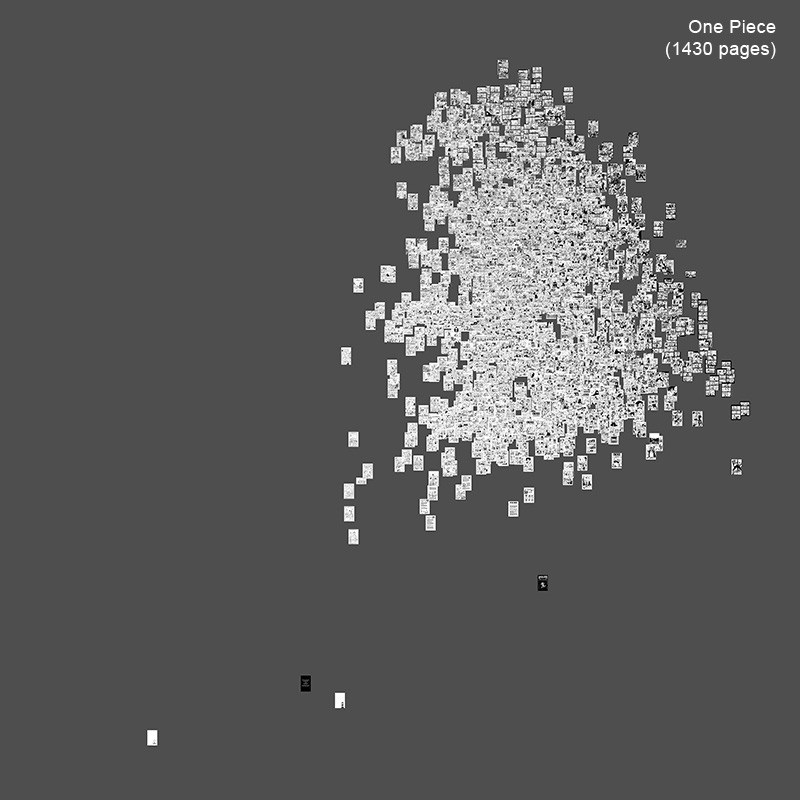
Сравнение Vampire Knight и One Piece (2,744 страниц)
Масштабы Abara и Noise довольно малы: 291 страница и 183 страницы соответственно. Как наш метод может проецироваться на более длинные серии манги, такие как Vampire Knight (57 глав, 1423 страницы) и One Piece (563 главы, 9745 страниц)?
Издание Vampire Knight началось в январе 2005 года, а выпуск One Piece начался с 4 августа 1997 года. Это объясняет различия в количестве глав и общих страниц в нашей выборке. Чтобы сделать сравнение более показательным, мы будем использовать только часть набора данных One Piece: 481-563 главы, которые содержат 1321 страницу. Как и в предыдущем примере, мы будем визуализировать эти два набора страниц в соответствии со стандартным отклонением (ось X) и энтропией (ось Y). График данных задействуется с использованием разброса участков; каждая страница представлена точкой.
Мы можем заметить, что центр точек в левом графике выше центра точек в правом. Напомним, что ось Y соответствует низкой текстурированности/детализации — высокой текстурированности/детализации. Это подтверждает то, что мы видим на двух примерах страниц: страница Vampire Knight имеет больше затенения и более высокую детализацию, чем страница One Piece. Однако, поскольку каждый набор точек также значительно расширяется по оси Y, ясно, что нам повезло в нашем выборе. Мы могли бы легко выбрать другие страницы, которые привели бы нас к противоположному выводу о графической разнице между двумя выборками.
Чтобы подтвердить наше наблюдение относительно разницы между двумя наборами точек на вертикали, мы вычисляем фактические средние значения данных, прогнозируемых на оси Y (энтропия).
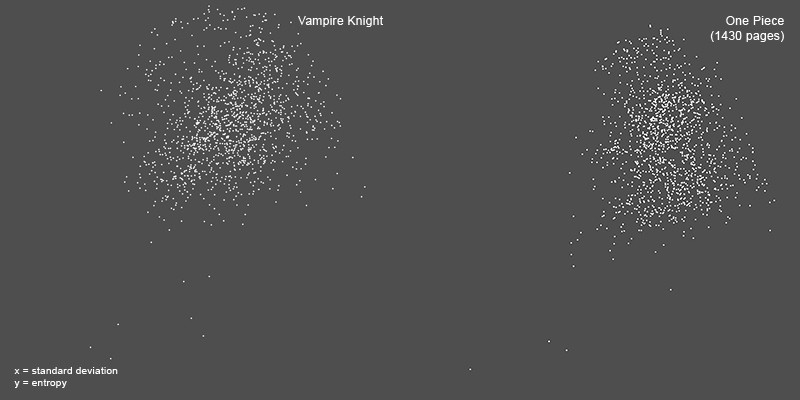
Vampire Knight: среднее значение энтропийных измерений 1423 страниц: 5,1. One Piece: среднее значение энтропийных измерений 1321 страниц: 5,6. (Средние значения округлены до одной цифры).
Чтобы увидеть эти значения в перспективе, будет нелишним знать максимально возможное значение энтропии. Измерение одного изображения составляет 7.962. Из этого видно, что данное значение составляет 6,4% от общего объёма возможной области.
Сравнение Naruto и One Piece (17 782 страниц)
Когда мы ставим рядом две типовые страницы из серии Manus, Naruto и One Piece, мы видим, что различия в их графических стилях являются менее явными, чем между типовыми страницами из Vampire Knight и One Piece. Можем ли мы лучше понять эти более тонкие различия, используя наш метод?
Интересно также сравнить Naruto (1999-) и One Piece (1997-), потому что они входят в число наиболее популярных серий манга в всем мире (1 и 3 места соответственно согласно OneManga.com (One Manga). К тому времени, когда мы скачали страницы с OneManga.com осенью 2009 года, первая серия уже публиковалась непрерывно в течение 10 лет, а вторая — на протяжении 12-ти. Соответственно, наша выборка содержала 8037 страниц Naruto и 9745 страниц One Piece.
Следующие графики сравнивают эти два набора страниц.

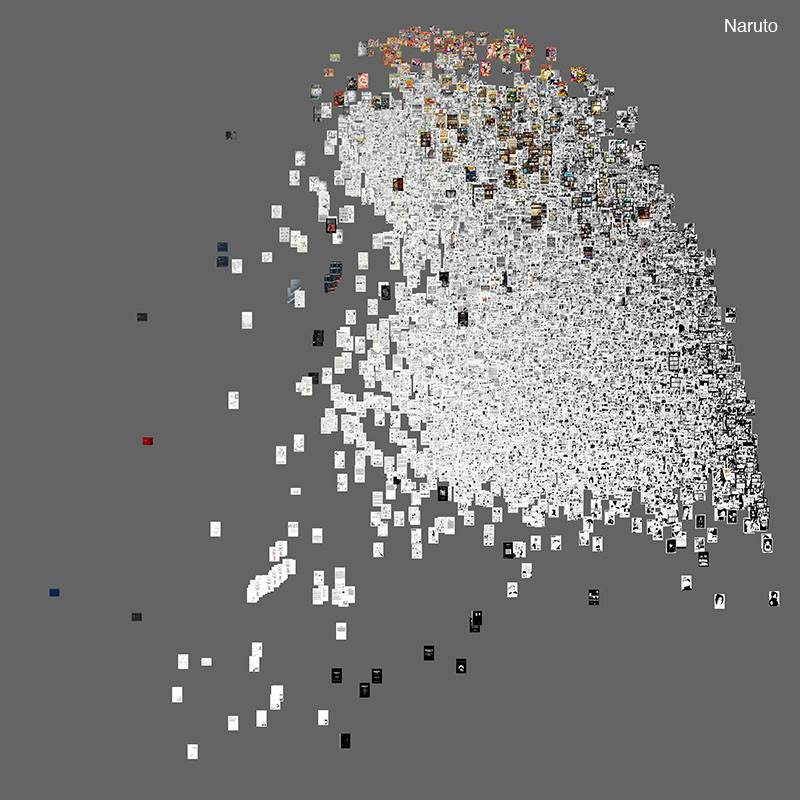
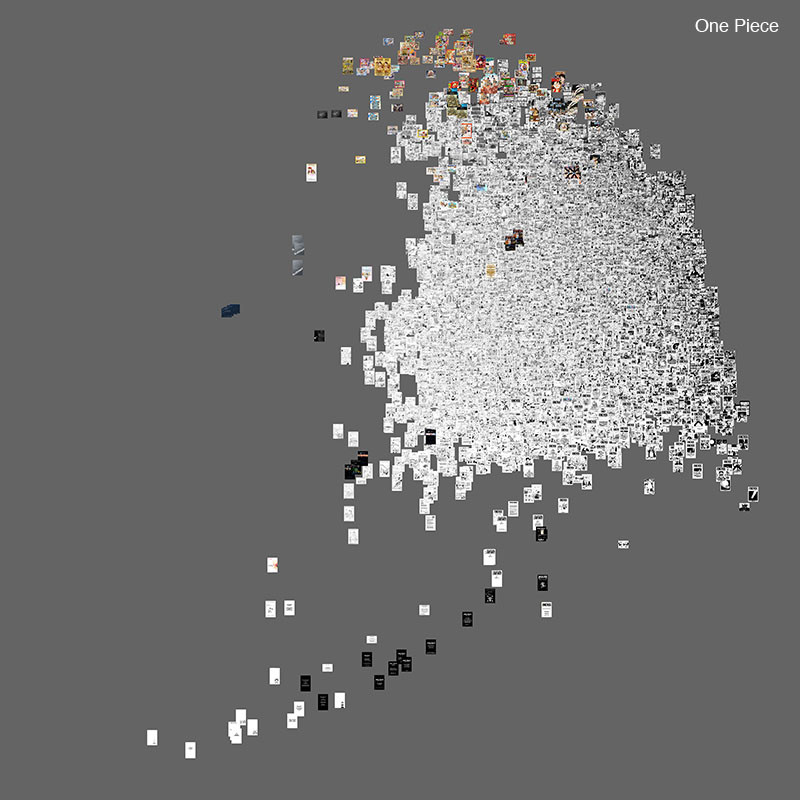
Проецирование большого количества страниц из двух рядов на одно и то же пространство координат помогает нам лучше понять сходства и различия между графическими стилями. На примере двух рассмотренных измерений визуализирование показывает, что различия между выразительными средствами двух серий являются количественными, а не качественными. То есть, «облако точек» страницы Naruto в значительной части пересекается с «облаком точек» страницы One Piece по обоим направлениям.
В то же время различий между ними больше, чем может отобразить случайное сопоставление двух страниц. На визуальных моделях мы видим, что обе серии охватывают широкий спектр графических возможностей: от простых чёрно-белых страниц с минимальной детализацией и текстурованием (нижняя часть) до очень подробных и текстурированных (верхняя часть). Но центр облака One Piece немного выше центра облака Naruto. Это означает, что One Piece имеет больше страниц с бо́льшим количеством текстур и деталей.
Визуализации также дают нам увидеть существенные различия в графической динамике означенных серий. «Облако точек» Naruto гораздо более рассеяно, чем у One Piece на обоих направлениях. Это указывает на то, что визуальный язык Naruto более разнообразен, чем у One Piece (мы уже видели аналогичную разницу, когда сравнивали Abara и NOISE, но теперь мы видим это на примере гораздо более объёмного набора данных).
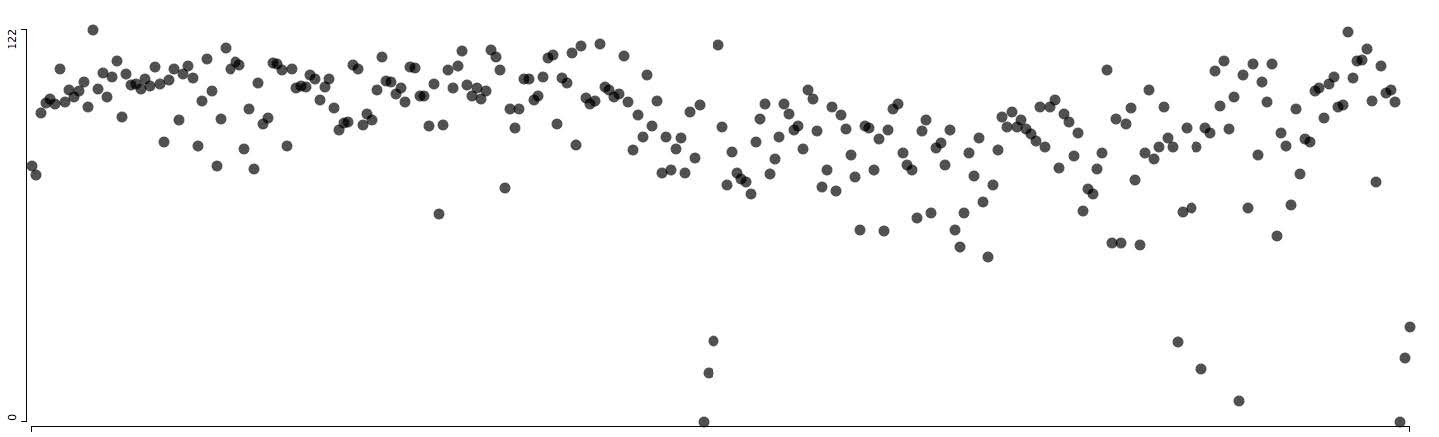
Мы так же можем рассмотреть стилистическое развитие этих длинных серии в динамике, как в случае с гораздо более короткими Abara и NOISE. Следующие графики — 9745 страниц One Piece слева направо в порядке публикации; вертикальное положение определяется по градации серого. Внизу графика — три примера страниц, на которые мы уже ссылались ранее.
Поскольку мы имеем дело с тысячами страниц в 562 еженедельных главах, опубликованных более чем за 12 лет, мы можем обсуждать временные закономерности по годам. По шкале лет, средние значения One Piece постепенно дрейфуют в течение всего времени. В этой общей почти линейной схеме мы наблюдаем периодические рост и упадок в пределах от 7 до 13 месяцев. Таким образом, мы получаем ответ на вопрос, который задавали ранее, когда сравнили три примера страниц, взятых из 5-й, 200-й и 400-й главы: как меняется визуальный язык One Piece со временем?
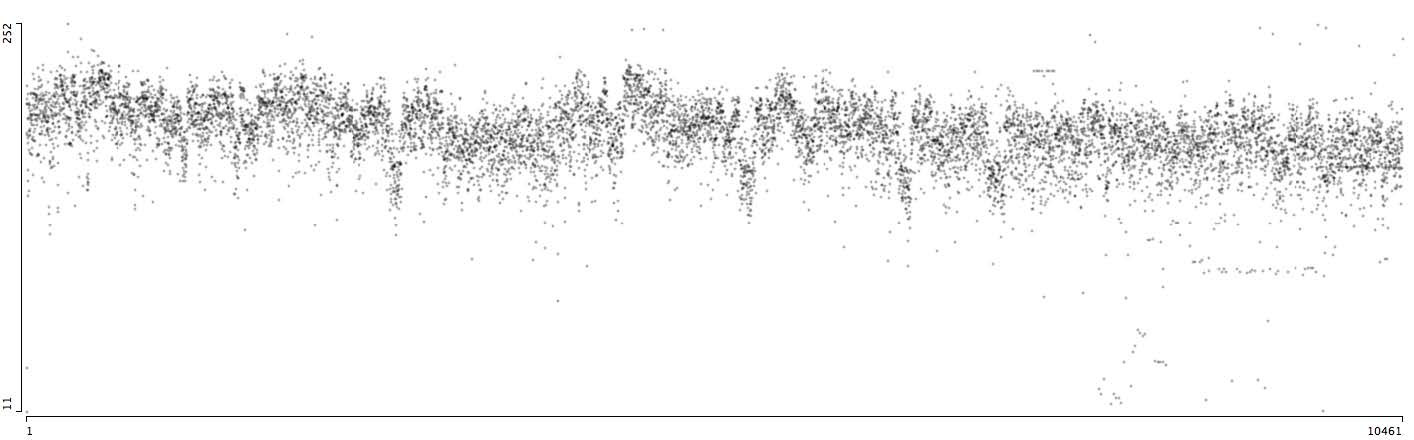

Исходя из модели также видим, что принципы могут быть незаметны, если мы используем лишь небольшое количество страниц. На трех сканах, которые мы видели ранее, пропущены оттенки серого, которые мы можем отметить в масштабе всех страниц. Они соответствуют фрагментам участков повествования, которые помещают кадры на черном фоне, как видно из крупного плана предыдущего монтажа всех страниц One Piece.

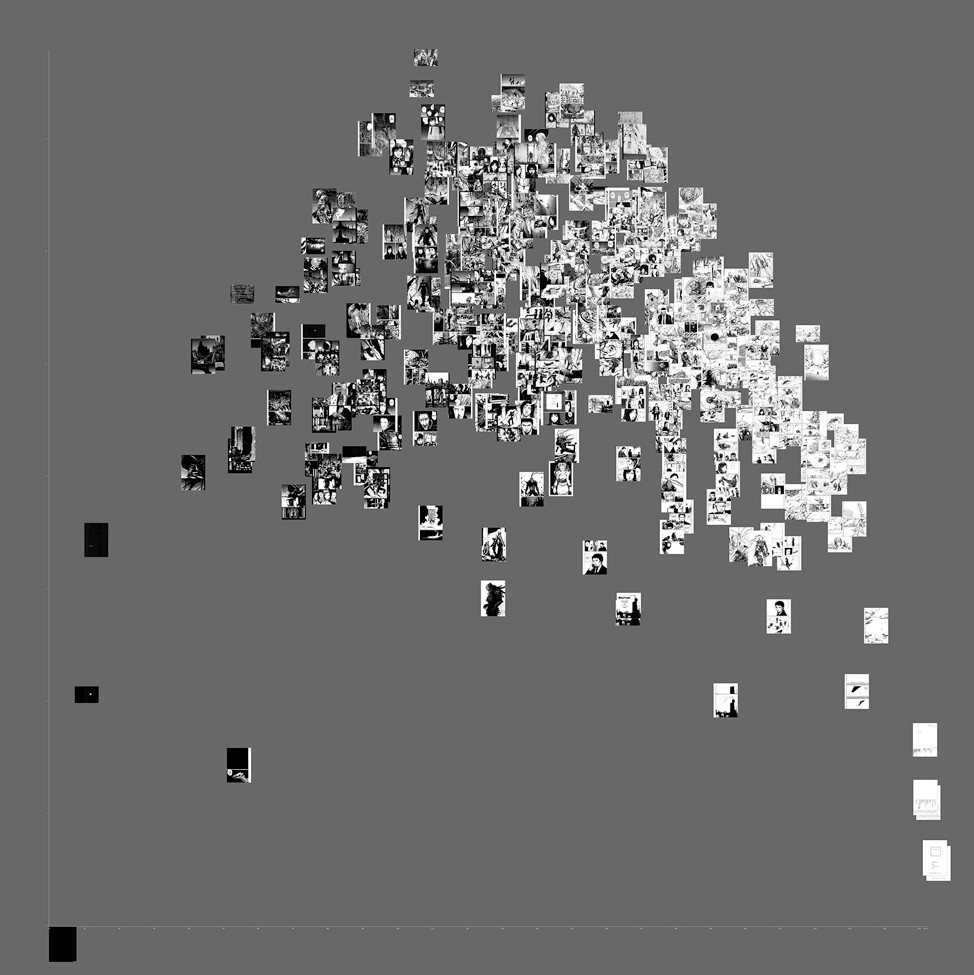
Визуализация полного комлекта манги (1 074 790 страниц)
Теперь мы можем, наконец, дать ответ на вопрос из заглавия: как увидеть миллион изображений? Используя те же измерения и значения осей (ось X = стандартное отклонение, ось Y = энтропия), как это делалось в случае с отдельными произведениями и сериями, мы визуализируем нашу полную выборку в миллион страниц (конечно, мы также можем вывести эту схему, полученную многими другими способами, задействовав иные параметры — это всего лишь одна из возможных моделей).



Один миллион страниц манги организован в соответствии с выбранными визуальными характеристиками.
Ось X = стандартное отклонение значений оттенков серого всех пикселей на странице.
Ось Y = энтропия, рассчитанная по значениям оттенков серого для всех пикселей на странице.
Верхнее изображение: полная визуализация.
Среднее изображение: крупный план верхней части.
Нижнее изображение: крупный план нижнего левого угла.
Примечания
1) Некоторые из страниц (например, все обложки) имеют цвет. Чтобы иметь возможность вместить все изображения в одну большую картинку (оригинал составляет 44 000×44 000 пикселей и масштабируется до 10 000×10 000 для отправки на Flickr), мы распределили содержимое по градациям цвета.
2) Поскольку страницы отображаются поверх друг друга, вы фактически не видите миллион отдельных страниц — скорее, визуализация показывает распределение всех страниц с типичными примерами, появляющимися сверху.
Один миллион страниц охватывает пространство графических возможностей более широко и с большей плотностью, чем Naruto или One Piece. Между четырьмя графическими крайностями, соответствующими левому, правому, верхнему и нижнему краям страниц «о́блака», мы находим все возможные промежуточные графики изменений. Это говорит о том, что графический язык манги следует понимать как непрерывную переменную.
В свою очередь, это предполагает, что сама концепция стиля, как он обычно понимается, может стать проблематичной, ведь мы рассматриваем очень большие корпуса медиа данных. Идея стиля подразумевает, что мы можем разбить набор произведений на небольшое число дискретных категорий. Однако, если мы видим, что разброс вариантов велик, а различия между ними малы (например, в нашем случае с миллионом страниц манги), то мы не можем пользоваться данной схемой. Вместо этого лучше задействовать визуализацию и математическое описание, характеризующие пространство возможных и реализованных вариантов.
Чтобы лучше понять распределение наших данных в пространстве всех графических возможностей, мы можем отобразить информацию из последней визуальной модели с помощью точек. Подобный график рассеяния не так просто читать как систему, однако так он лучше показывает принцип распределения страниц. Сюжет же показывает, что распределение следует по кривой Белла: перед нами единичные плотные кластеры с постепенным снижением по краям. Участки сюжета в чёрном цвете представляют собой графические возможности, не представленные в нашем примере: почти полностью белые изображения (нижний правый угол), и изображения, которые имеют обширные области чёрного и малые области белого (левая треть участка).

Тот факт, что обработка цифровых изображений и визуализация набора данных в миллион страниц манги заставляют нас поставить под сомнение основную концепцию гуманитарных наук и сам институт критики, по крайней мере так же важен, как и любые открытия, которые мы можем сделать исходя из этого набора данных. Он иллюстрирует, как вычислительный анализ массивных блоков медиаданных может трансформировать наши теоретические и методологические парадигмы исследования культуры.
ОСТРАНЕНИЕ С ПОМОЩЬЮ КОМПЬЮТЕРОВ

Наша методология опирается на стандартные средства анализа цифровых изображений, которые были разработаны уже во второй половине 1950-х годов и теперь повсюду (в цифровых камерах, программном обеспечении для редактирования изображений, таких как Photoshop, автоматизированных фабриках, медицинских визуальных моделях и всех областях науки, которые используют изображения как источник данных (от астрономии до биологии)). Однако, когда мы принимаем эти методы в качестве инструмента для исследования культуры, нам должно быть ясно, как они анализируют изображения и что они означают, в общем, взгляд сквозь «компьютерные очки». Поскольку в этой главе внимание сосредоточено на мотивации и объяснении нашего метода в общих чертах, мы можем сделать следующее общее заключение. Когда мы смотрим на изображения привычным взглядом, мы сразу ощущаем все их визуальные характеристики.
Когда же мы рассматриваем эти характеристики с помощью цифрового анализа изображений и визуальных моделей, мы разрушаем этот опыт целостности. Возможность исследовать корпус изображений, задействуя особую визуальную размерность, — это мощный механизм осознания («отстранения»), способ увидеть то, что мы могли бы не заметить ранее. Если авангардные фотографы, дизайнеры и режиссеры 1920-х годов (такие как Родченко, Мохоли-Наги, Эйзенштейн и Вертов) опровергли стандартное восприятие видимой реальности с помощью диагонального кадрирования и необычных точек зрения, то теперь мы можем использовать программное обеспечение для перенастройки нашего восприятия визуальных и медиа культур.
Благодарности
Исследование Инициативы по исследованиям в области программного обеспечения, о которых сообщалось в этой статье, стало возможным благодаря щедрой поддержке, предоставляемой Калифорнийским институтом телекоммуникаций и информации (Calit2), Центром исследований в области вычислительной техники и искусств в UCSD (CRCA) и ректората Университета Калифорния, Сан-Диего (UCSD). Разработка специализированного программного обеспечения для анализа цифровых изображений и обработки изображений манги, установленного на суперкомпьютерах в Национальном энергетическом научно-исследовательском Вычислительном центре (NERSC) была профинансирована в 2009 году HEN Humanities High Performance Computing, Премия «Визуализация шаблонов в базах данных, содержащих изображения визуальной культуры и видео». Разработка Программного обеспечения ImagePlot финансировалась грантом NEH 2010-2011 Digital Startup level II «Интерактивная Визуальная модель собрания изображений для гуманитарных исследований».
Также
Инструменты визуализации и анализа данных и визуальных моделей разработаны Software Studies. Данная инициатива — результат систематического сотрудничества между ключевыми членами лаборатории: Лев Манович, Джереми Дуглас, Уильям Хубер и Тара Цепель. Программное обеспечение HyperSpace для интерактивных носителей визуальных моделей была разработана Со Ямаока (Gravity lab, Calit2). Средства пакетной обработки изображений были разработаны Сансерн Чеаманункул (аспирант, отдел информатики и инженерии, UCSD).
Рекомендации
Барри, Сол. Статистический анализ стилей в кино. 1974. Film Quarterly, 28, 1: 13-22.
Барри, Сол. Стиль и технология фильма: история и анализ. Лондон: Starword, 1992.
Ча, Мийонг, Хьявун Квак, Пабло Родригез, Янг-Яол Ан и Сью Мун. «I Tube, You Tube»; «Все трубы: анализ самой большой в мире базы пользовательского видеоконтента». 2007 ACM Интернет-конференция по измерению. Web. 17 июля 2011 года. .
Cinemetrics.lv. База данных Барри Солт. Web. 11 августа 2011 года.
Крэнделл, Дэвид Дж., Ларс Бэкстром, Даниэль Хаттенлочер, Джон Клейнберг. Отображение фотографий в мире.18-я международная конференция по всемирной сети, 2009. Web. 17 июля 2011 года. .
Дуглас, Джереми, Уильям Хубер, Лев Манович. «Понимание сканирования: как читать один миллион манга-страниц, переведённых фанатами». Image and Narrative, 12, 1 (2011), 190-228. .
Фильтр Габора. «Фильтр Габора». Википедия. Web. 11 августа 2011 года. .
Херринг, Сьюзан, Лоис Энн Шейдт, Инна Купер и Илия Райт. Продольный анализ содержимого блогов: 2003-2004 гг. Блоги, гражданское общество и будущее СМИ. Лондон: Routledge, 2006.
IMDb. Статистика базы данных IMDb. Web. 17 июля 2011 г. .
Квак, Хауэун, Чанхьюнь Ли, Хосунг-Парк и
Инициатива по изучению программного обеспечения. ImagePlot. Программное обеспечение с открытым исходным кодом для визуализации больших собраний изображений и видео. Web.
Маклуд, Скотт. Понимание комиксов: Невидимое искусство. Kitchen Sink Press, 1993.
Манович, Лев. «Культурная аналитика: визуализация культурных образцов в эпоху “всеобщей медийности”». Domus, Весна 2009 года. Web. .
Манович, Лев. 2010. «Визуализация мультимедиа: визуальные методы для изучения больших собраний медиа». «Фьючерсы в медиа», издательство Келли Гейтс. Блэквелл, 2012 год. 17 июля 2011 года.
Web. .
Моретти, Франко. Гипотезы относительно мировой литературы. New Left Review 1 (2000), 55-67. 17 июля 2011 года. Web. .
One Manga. onemanga.com список лучших 50 манг. 12 августа 2011 года. .
Питерс, Кэрол, изд. MultiMatch: Технологическое обучение и доступ к культурному наследию. D1.1.3 — Раздел отчета об искусстве. 2006. 17 июля 2011 г. Web.
Трейсман, Энн и Гарри Геладе (1980). «Теория интеграции функций». Когнитивная психология, т. 12, № 1, стр. 97-136.
Уорд, Л.М. (декабрь 2003 г.). «Синхронные нейронные колебания и когнитивные процессы». Тенденции когнитивной науки 7 (12): 553-9.
Уильямс, Д., Н. Мартинс, М. Консальво и Дж. Ивори. 2009. «Виртуальная перепись: Представления пола, расы и возраста в видеоиграх». Новые медиа и общество. 11, п. 815-834.
Ямаока, С., Л. Манович, Дж. Дуглас, Ф. Кюстер. 2011. «Культурная аналитика в крупном масштабе. Визуальные модели в медиа». Представлено на форуме компьютерной графики.
