Бытовые архивы современного человека
Информационный архитектор в Infodesk и

Любой человек с определенного возраста достаточно быстро начинает сталкиваться с нарастающей массой собственного имущества (книг, одежды, домашней утвари, фотографий, писем), а также бумажек, которые совершенно необходимо хранить примерно всю жизнь: личные документы, документы на недвижимость, коммунальные счета, банковские выписки, гарантии на технику и еще целый ворох других. К счастью, многое из перечисленного сейчас перемещается в цифровую среду и хотя бы начинает занимать меньше физического места.
В обоих случаях остро встает вопрос организации этих ресурсов. В цифровой среде, проблема упорядочивания тем актуальнее, что процесс накопления разного типа данных, никак не ограничиваемый пространственными рамками, набирает обороты с чудовищной скоростью.
Для того, чтобы каждый объект в нужный момент был под рукой, важно не только суметь его сохранить, но и разработать логичную систему описания, организации и размещения объектов, помогающую поиску. Далеко не каждый человек хочет и может такую систему построить, — у многих все хранится в неструктурированной куче, — но в случае выполнения этих условий, можно говорить о создании архива (в широком смысле).
Но
Сложно построить систему
Большим преимуществом цифровой среды с точки зрения упорядочивания информации являются предусмотренные различными сервисами и приложениями инструменты систематизации контента. Один инструмент для вертикальной иерархичной организации знают все: вряд ли есть человек, который бы никогда не использовал вложенные друг в друга папки для хранения файлов на своем компьютере.
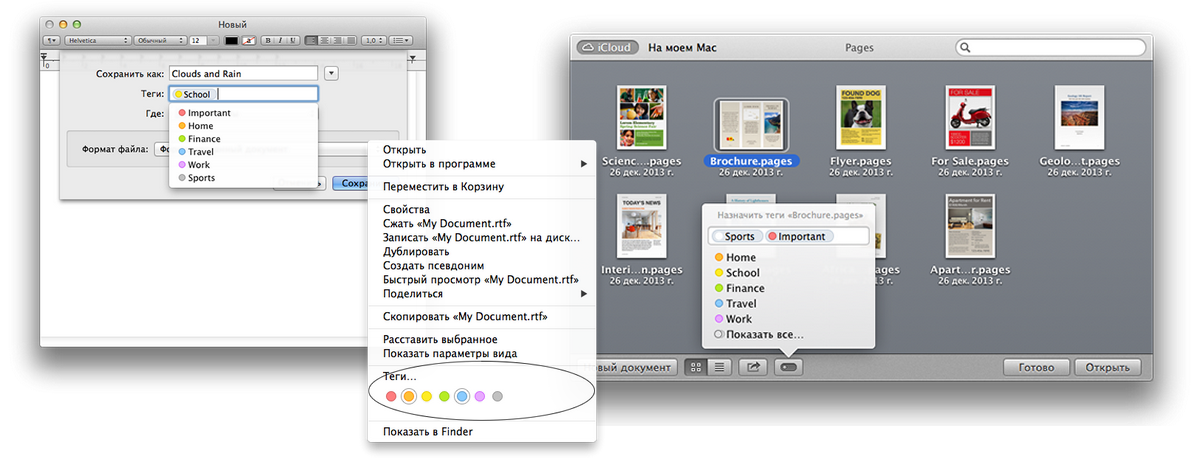
А в 2013 году Apple выпустил операционную систему Mavericks, позволяющую файлы еще и тегировать — помечать короткими ключевыми словами. Cпособ далеко не новый, но к операционной системе был применен впервые. Тегирование задает горизонтальную, сетевую систему организации: любые файлы можно пометить одним или несколькими тегами. Вбив тег в поле поиска или выбрав его из списка (облака) всех созданных тегов, можно получить набор всех файлов, им помеченных, вне зависимости от того, в каких папках они лежат и как называются.
Эти два базовых инструмента, папки и теги (перечисление всех особенностей каждого из них, на самом деле, требует значительно более подробного описания) встречаются повсеместно: в закладочных сервисах, rss-ридерах, почтовых клиентах, системах управления проектами, соцсетях. Но, несмотря на такую распространенность, достаточно мало людей умеют корректно ими пользоваться. Для того, чтобы выстроить систему организации с помощью этих инструментов, нужно сначала понять: что ты организуешь, по каким параметрам, как параметры между собой связаны. А набор параметров часто зависит от того, зачем и для кого создается структурированная система.
Только глядя через призму последних двух вопросов, можно подробно описать все сохраняемые элементы и выделить минимальный набор релевантных параметров, который позволит правильно выбрать систему организации, разместить в ней элементы, а значения параметров помогут пользователю найти любой из них (размер, цвет, тип, медиа → маленькое, черное, платье, фотография).
В противном случае, получаются, например, ситуации, когда тегов в несколько раз больше, чем протегированных ими объектов, что вовсе не помогает поиску. Или когда огромное количество совершенно разнородных объектов помечены общим тегом, который тут же теряет свой навигационный смысл. Или когда не знаешь, где в некорректно выстроенной иерархии место для скачанной с Амазона книги Information Design: в папке «книги», «дизайн» или «образование».
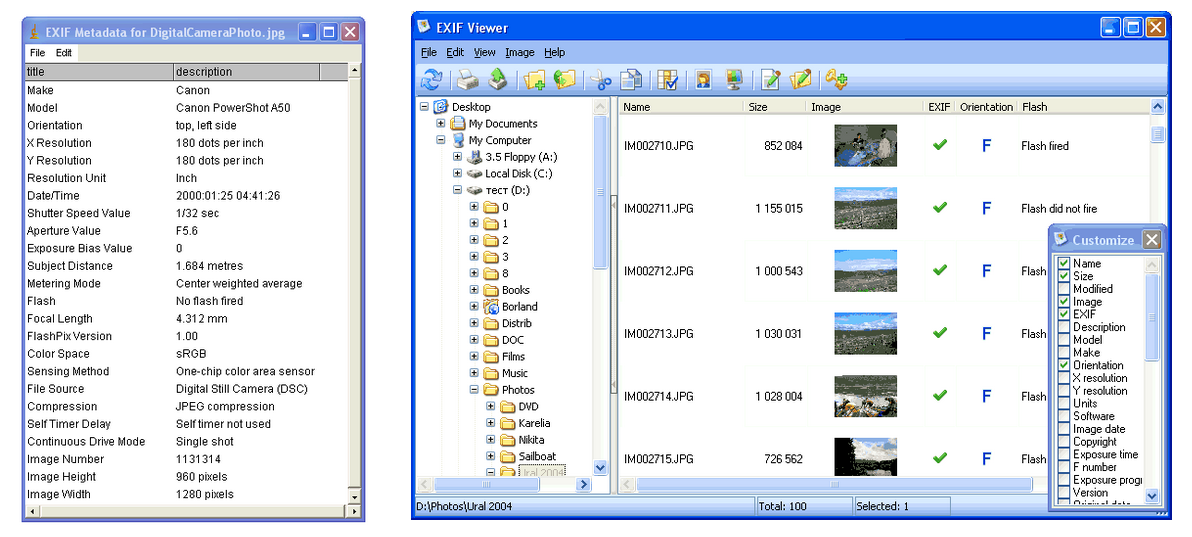
Вторым цифровым удобством, облегчающим организацию архива как раз с точки зрения описания его элементов, является существование для многих ресурсов уже разработанных описательных схем — от самых общих (Dublin Core), до очень глубоких и узкоспециализированных (CDWA, vCard, Exif). Их используют, чтобы создавать мета-описания, которые позволяют, например, поисковым механизмам формировать релевантную вашему запросу выдачу.
Но и для задач попроще они тоже полезны: библиотекари, музейщики, архивариусы и просто люди, которым нужно что-то структурировать, могут использовать эти схемы в качестве справочника, в котором всегда можно посмотреть, с помощью каких параметров принято описывать ту или иную область, и создать на базе него свою систему тегов или иерархию папок.
Кроме того, в некоторых случаях мета-описания автоматически присваиваются определенным объектам. Например, практически все цифровые фотографии снабжены Exif-описанием, которым их снабжают фотокамеры. В нем может находиться информация о параметрах съемки (диафрагма, выдержка…), самой камеры (марка, модель), месте съемки и многое другое. Если вас устраивает такая система описания и организации фотоархива, можно ее использовать (и в определенных рамках — дополнять), не придумывая собственную. Автоматические системы (еще один, более известный, пример: Google Tabs and Categories) безусловно экономят время, однако всегда будут для вас менее точными, чем самостоятельно проработаная структура.
Объемы поступающей информации не оставляют времени на ее организацию
Даже если человек как следует продумал систему описания и хранения, у него возникают другие проблемы, мешающие качественной организации цифровых архивов.
Одна из них — очень быстро накапливающийся объем сохраняемых данных. С телефонов и фотоаппаратов без отбора выгружаются в облако или на жесткий диск огромные массивы фотографий. Ссылки на статьи, сервисные сайты, новостные ресурсы превращают закладки браузера в темный лес. Количество рабочих файлов с презентациями, pdf, doc по разным проектам захламляют рабочий стол. Важные письма за день уходят на вторую, третью страницу почтового клиента.

Такие скорости зачастую не позволяют уделять достаточно времени тому, чтобы как следует продумывать, куда ты кладешь конкретный файл или ссылку, как ее описываешь. Проблему частично можно решить, самостоятельно прописав контекстные правила обработки контента. В некоторых сервисах для этого предусмотрены внутренние настройки (например, настройки правил тегирования и пересылки в Gmail), в других случаях удобно использовать отдельные триггерные инструменты типа IFTTT.
Другое решение — использование автоматических инструментов для структурирования поступающего контента. Выше они упоминались в контексте избавления человека от необходимости придумывать свой способ организации. Здесь же хочется сделать акцент на том, что они экономят пользователю время, самостоятельно распределяя контент в рамках заложенной в них системы. Однако, ввиду того, что их алгоритмы построены на неком обобщенном представлении о потребностях пользователя, они часто не могут удовлетворить более специфические нужды.
Архивы устаревают
Во-первых, человек меняется. Его информационный контекст — тоже. На одни и те же ресурсы — документы, фотографии, статьи, сайты — в разные периоды жизни или в рамках разных рабочих проектов можно смотреть совершенно по-разному. Соответственно, то, как человек описывает элемент и то, куда он его сохраняет в одном контексте, может сильно отличаться от описания и сохранения того же элемента в другом контексте. Осуществлять поиск в таком мультиконтекстном архиве достаточно сложно.
Во-вторых, устаревает сама хранимая информация. И, в-третьих, появляются новые (для человека) типы информации и новые (для IT индустрии) форматы, требующие новых подходов к описанию.
В этом устаревании заключается третья проблема, которой, насколько я знаю, решения пока не нашлось. Тут хочется помечтать о механизмах, анализирующих спектр потребляемых тобой здесь и сейчас данных, их семантику, особенности форматов, и предлагающих переместить вот эту закладку или документ в другую папку, переназвать его, поменять теги, удалить вот это, это и это, как нерелевантное или не отвечающее кругу твоих актуальных интересов.
Без постоянного обновления содержания и системы организации архив превращается в красиво оформленный срез определенного отрезка жизни его автора в определенной среде (иногда возникает желание рассматривать это как своего рода объект современного искусства), но теряет свою функциональность.
«Зачем?» и «Для кого?»
В тексте выше речь шла о проблемах, с которыми сталкивается человек при создании архива для личного пользования, и о подходах к их решению. В случае, если систематизированная база материалов создается для того, чтобы делиться ей с другими людьми, описанные требования к структурированию остаются релевантными, но появляется дополнительный смысловой уровень организации, который важно хорошо продумать. Этот уровень представляет из себя такое «руководство пользователя», вручаемое автором своей аудитории: его комментарии или их отсутствие, определенный порядок изучения базы или полная свобода, выраженный угол зрения или пространство для интерпретации, — все, что так или иначе, позволяет увидеть собранные материалы так, он как задумал.
Чтобы правильно выстроить этот уровень организации, имеет смысл задать себе вопросы: «кто будет этим пользоваться?», «с какой целью?». И ответить на них. Автор должен понимать, что выступает в качестве куратора, и, в зависимости от задачи, стараться усиливать или сокращать свое присутствие.
Например, если нужно собрать материалы, которые должна мочь использовать в качестве справочника (то есть, для самостоятельного поиска информации в разных контекстах) большая и разнородная аудитория, неплохо бы сначала ознакомиться с наиболее частыми общими терминами, применяемыми для описания каждого из материалов. И учесть их при создании системы организации.
Если база содержит элементы, которые автор хочет осветить лишь в одной плоскости, при этом не тратя лишних сил на объяснение пользователю, под каким углом следует рассматривать архив, не стоит ориентироваться на частые общие термины, но, скорее, ограничиться теми, которые специфичны для его угла зрения. Таким образом внешнему человеку, с одной стороны, дается свобода изучения всего массива материалов в любой последовательности, с другой, угол зрения, под которым он на него смотрит, все же ограничивается.
В случае, если составителю базы важно последовательно «провести» пользователя по своему архиву (обучить, рассказать), на все стандартные организационные приемы (или вместо них) накладывается слой, обеспечивающий заданный линейный порядок взаимодействия человека с базой и, например, текстовые аннотации в свободной форме. Это выводит автора на первый план, подчеркивает его функцию куратора и помогает аудитории точнее понять структуру и задачи массива данных.
Структурирование информации — работа всегда непростая, многомерная, подразумевающая понимание задач, аудитории, особенностей элементов, приложение интеллектуальных усилий и трату большого количества времени. Особенно времени. Каждый решает сам: расходовать его на вдумчивую организацию или на поиск в неорганизованной куче.
Что читать

